

前言
闲来无事,利用课余的时间完成的采集脚本,实现了采集月光博客所有公开文章并分别以文本文档进行另存为,代码量虽少但做到了利用最大化,此方法还是以正则为中心,利用while与foreach的循环遍历操作进行实现。
实现思路:自增pageID,使用while进行循环GET拼接PageID后的URL,循环内部取得整个页面的字符串后利用正则提取出单Page页所有博文的文章URL与标题,再次以foreach循环遍历结果集,循环内部对遍历出来的URL再次GET后对返回结果进行正则匹配目的就是提取出文章的内容(一个标题对应一篇文章,因此不用担心在遍历循环的时候出现逻辑上的错误),万事俱备只欠东风,拼接路径依次写入。
warning:此次采集只为用作学习交流,采集得到的文章不会进行二次修改发布,更不会用于商业。文章著作权归原PO持有,采集方案归本人所有,转载请注明出处。
code
header("content-type:text/html;charset=urf-8");
ini_set('max_execution_time', '0');
$page = 1;
while($str = file_get_contents('http://www.williamlong.info/cat/?page=' . $page)){
$preg = '#<h2sclass=".*?"><ashref="(.*?)"srel=".*?">(.*?)</a></h2>#';
$result = preg_match_all($preg,$str,$arr);
if($result){
foreach($arr[2] as $key=>$value){
$content = file_get_contents($arr[1][$key]);
$preg = '#<divsid="artibody">(.*?)<psstyle="display:none;"sclass="cloudreamHelperLink"scodetype="post"sentryid="d+"></p></div>#';
preg_match($preg,$content,$newc);
if(!file_exists('./williamlong/html/')) mkdir('./williamlong/html/',0777,true);
file_put_contents(iconv("utf-8","gb2312","./williamlong/{$value}.txt"),$newc[1]);
file_put_contents(iconv("utf-8","gb2312","./williamlong/html/{$value}.html"),$content);
}
$page++;
} else{
echo '匹配失败';
return false;
}
}
最终效果
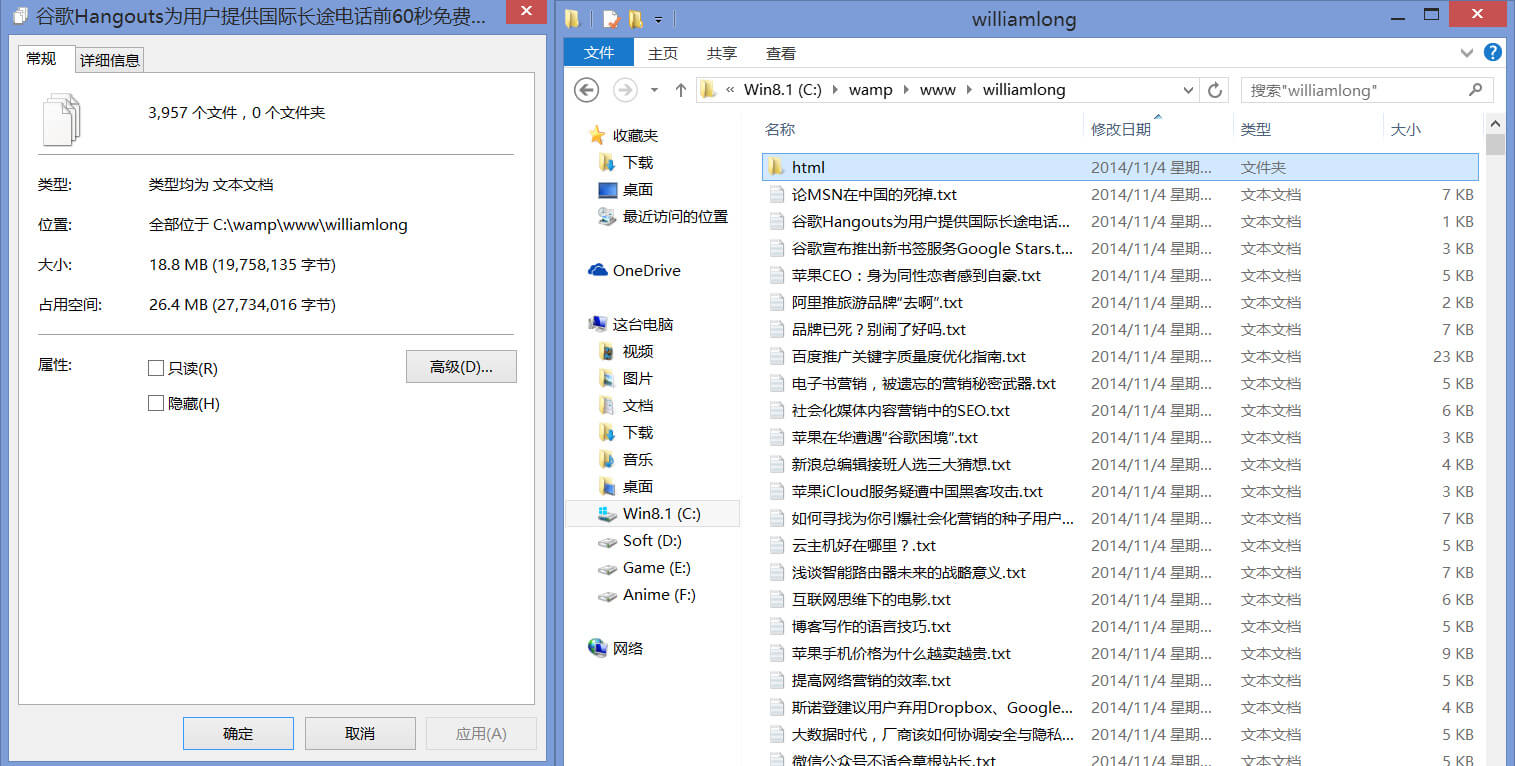


Comments | 6 条评论 (这是个静态化页面,评论后要等CDN刷新啦~)
为什么要强制编码转换再储存QWQ
原生的file_get_contents万一来个超时简直无情,这里踩过无数坑 /W
(p.s:度娘的划词分享简直反人类……
@千与琥珀
不然会乱码。windows中文版系统用的字符编码是gb2312,必须转后再存文件名就不会出现乱码问题。
超时一般不会,除非对方服务器炒鸡炒鸡慢
@音風
我的直接存utf8竟然没乱码……
反正这个函数踩了不少坑,读网页还是动用curl靠谱
@千与琥珀
hhhh 最主要还是file_get_contents方便省事~一个函数就解决的事情,也不必要用到curl了,那东西玩post提交的时候还好,如果只是不带cookie的普通get,file_get_contents还是不错的选择
@千与琥珀
内容不会乱码,因为记事本还是支持utf-8编码的。但文件名的话就觉得会乱码哦~除非你不用中文。。。
@音風
原来是奇葩的文件名……
不过我没用过中文保存文件名,避免各种你懂的